自分は仕事で電話機のカメラアプリ開発を手伝っている。 なのでカメラアプリから見るとどうかを中心に議論してみたい。
電話機の CPU はどのくらい使われているのか
電話機の CPU, 最近だと 8 コアくらいある。こいつらを活用したい。
わけだけれど、まず現実にはどのくらい活用されているのか実例を眺めてみる。 ちょっと前に自分のブログで Perfetto というトレーシングツール (プロファイラだと思ってください)を紹介した。 その中で実際にいくつかのアプリのトレースを集めた。手頃な実例になっている。
アプリの起動
このデータ をダウンロードして、ui.perfetto.dev から開いてほしい。 以下画面写真:
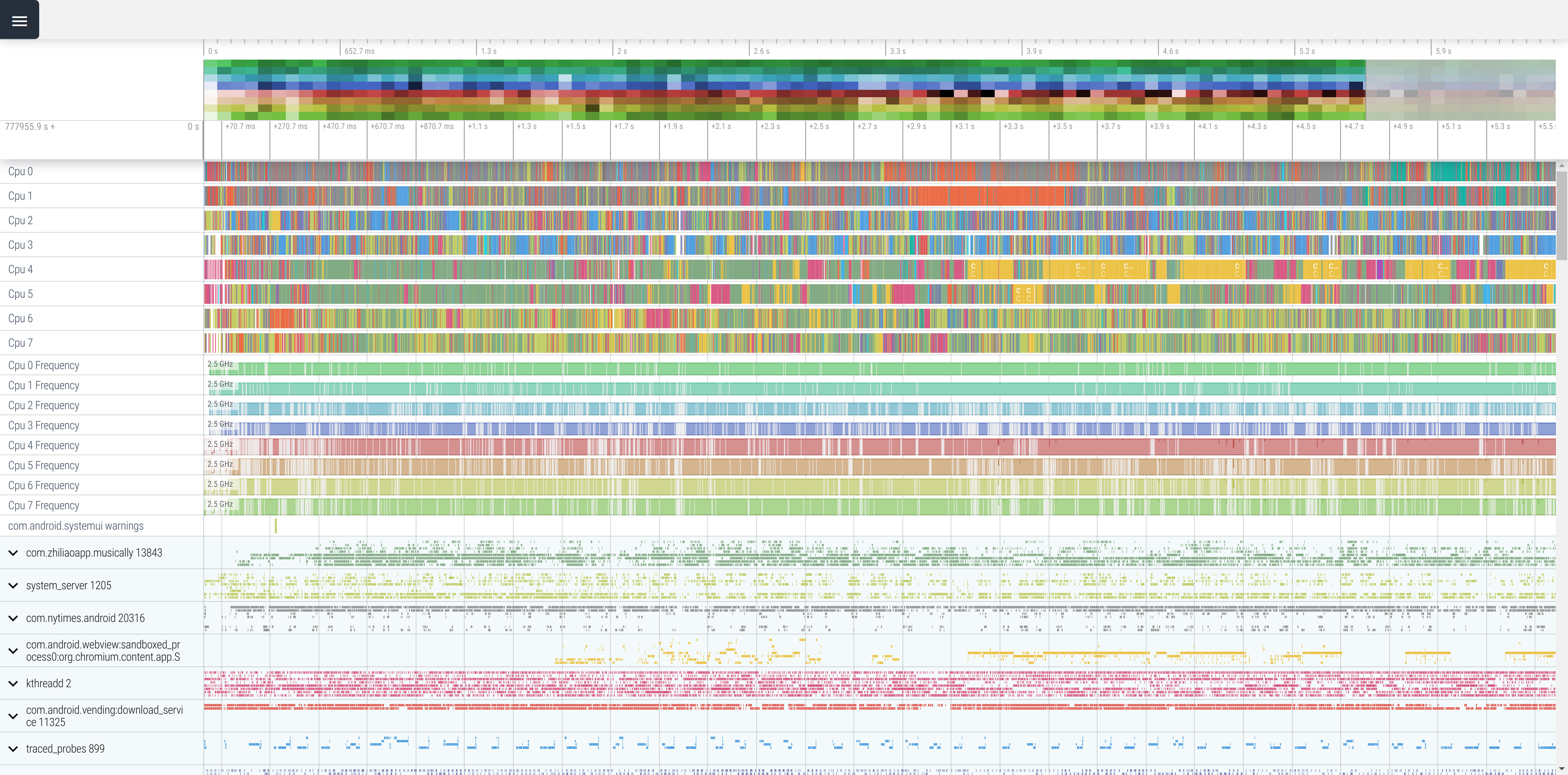
このトレースは Pixel 2 という電話機の上で TikTok というアプリの起動直後 5 秒間をキャプチャしている。 細かいところはわからなくていいけど、“CPU 0” から “CPU 7” までの行に細かい線が詰まっているのが見えると思う。
ちょっとズームインすると何がおきているかもう少しわかる。 これは起動 500ms 後くらい。
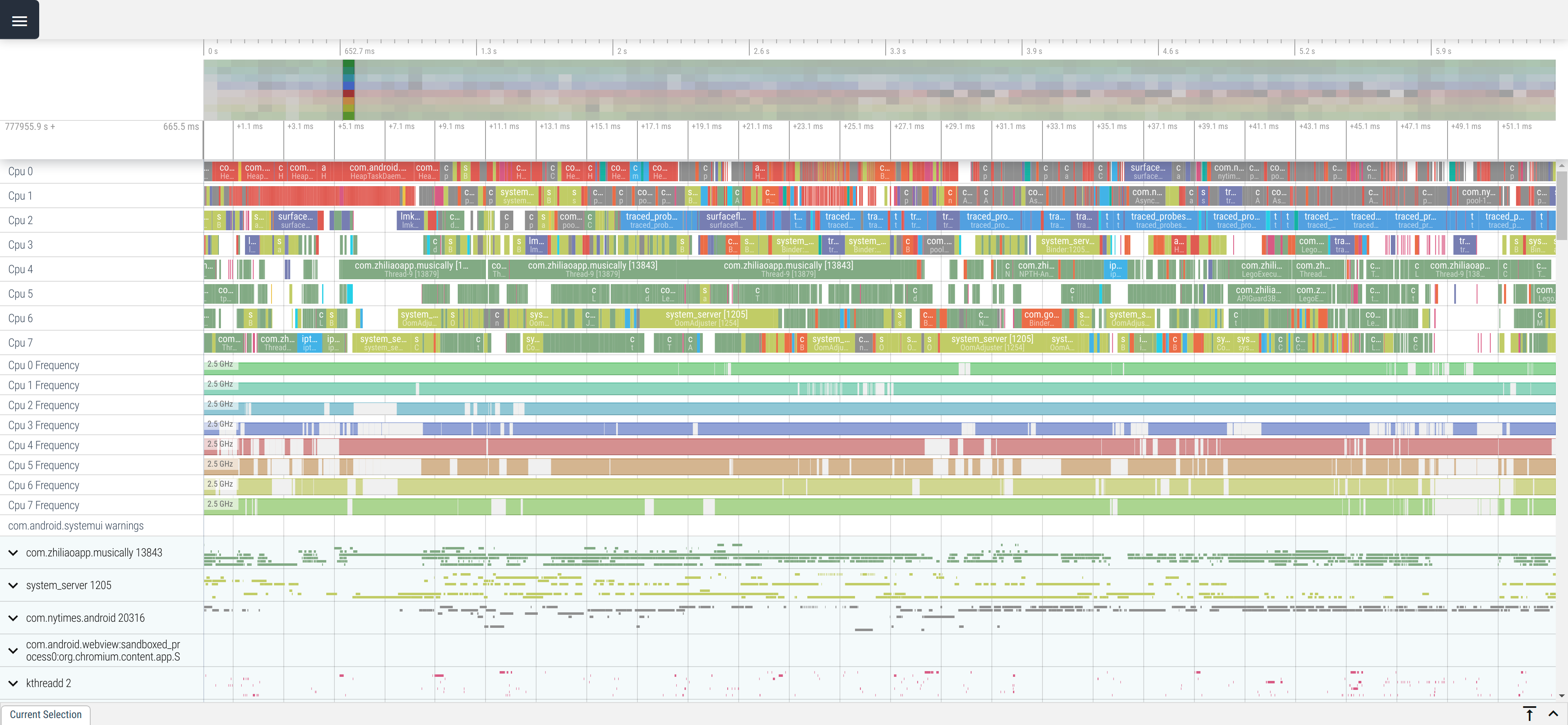
各 CPU がいつどのスレッドに使われているのか、時系列で可視化されているのがわかる。 隙間の空白は CPU が何もしていない瞬間を示している。
わかること: TikTok 起動の瞬間は CPU がそれなりに使われている。 目一杯限界まで使われているとは言わないけれど、半分以上は埋まってる。 自分は仕事でよく「起動が遅いのなんとかして」と送りつけられて来るトレースを睨む。 そういう「遅い起動」のトレースは CPU のタスクがもっとびっちり詰まっているのも珍しくない。 というかアプリの起動が遅い時、だいたい CPU は目一杯使われている。(みんな電話機酷使しすぎだよ・・・)
一体だれが CPU を使っているのか。Perfetto はそれも簡単に調べられる。 起動後二秒くらいを適当に切り出してプロセス単位の CPU 使用時間を眺めると…
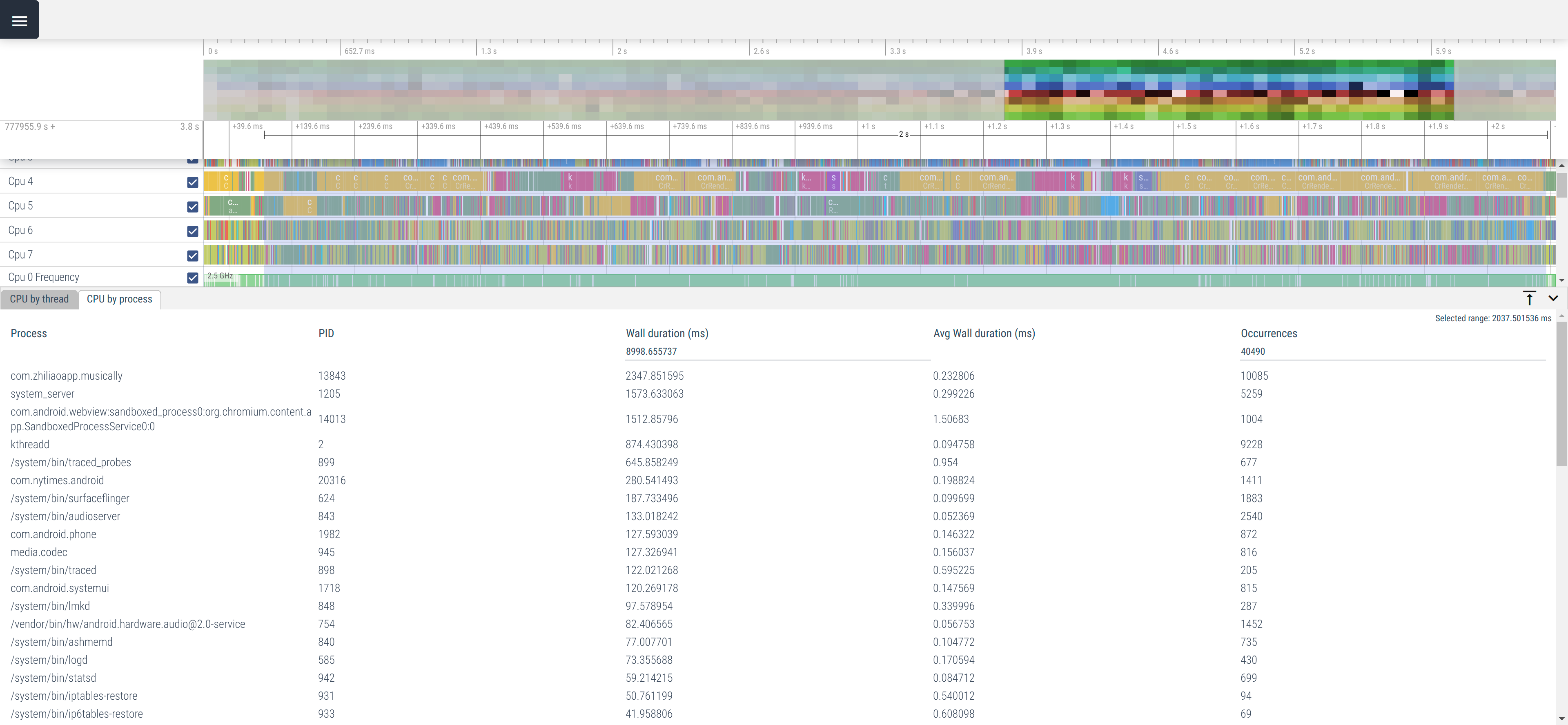
com.zhiliaoapp.musically が TikTok. たしかに一番 CPU を使っているけれど、
他にも Android のサービスをまるごとホストしたデーモンの system_server, Out-Of-Process された WebView, kthreadd(Linux カーネル)
などもわりと熱心に活動されている。直前まで開いていた NYTimes のアプリもいる。
仕事でやっているカメラアプリだと、このほかに Camera HAL (ユーザランドのドライバみたいなものです) も コア 1-2 個分くらいなんかしてる。
なおここでいう「アプリの起動」にはマルチタスクでのアプリ切り替えも含まれている。 Android ではアプリ切り替えと launcher からのアプリ起動に大きな違いはない。 Social media addict 気味の人が複数アプリを zap したりするの、電話機的には割と過酷。
アプリの起動後しばらくすると背後の様々なノイズは収まって、 メインのアプリ(と、そのアプリが使っているサブシステム)が 8 コアのうち 6-7 コアくらいは専有できるようになる。 3-4 秒後くらいかな。
ただし WiFi や Cellular のネットワークが切り替わったり (geofencing) サーバから push が降ってきたりするとまた騒がしくなる。 電子書籍アプリの仕事をしていたときに「遅い」とよこされるトレースは、 だいたいネットワークが切り替わるタイミングに背後でもぞもぞしている奴らのせいだった。 (歩きスマホはご遠慮ください。)
そんなかんじで、少なくともアプリ起動直後の CPU は割と忙しい。 沢山のアプリを行ったり来たりするヘビーユーザーならコア数が倍になってもそれなりに使える気がする。 逆に言うと long tail のアプリの起動を速くしたいなら現状だと並列化はそんなに効かない。 背後の活動に押されて起動中のアプリ自体は CPU 2-3 個ぶんくらいしか使えないから。 あと本題とは関係ないけど I/O 律速なことも多い。
レイテンシ重視と Heterogeneous Cores
Android での性能改善では起動および画面遷移の時間短縮と Jank-free すなわちコマ落ちしないことに重点がある。 実際のアプリではネットワークリクエストのレイテンシ最適化が一番大切だろうけど、それはコアの話に直接関係ないので置いておく。
起動ではまあまあコアを使い切れているのは先に書いたとおり。画面遷移は起動の小規模版という風情。
Jank はどうか。というと、レンダリングのパイプラインはそれほど並列化されてない。 もちろん「パイプライン」というくらいなのでステージへの分割は一定程度されている。 たとえばレイアウトのち描画を指示するメインスレッドと、描画の指示に従って実際に GL の API を呼ぶ RenderThread はわかれているし、 描画結果の画像を画面に合成する SurfaceFlinger も別プロセス。 画面に貼り付ける JPEG のデコードもワーカーでやる。React Native とかだとレイアウトも別スレッド。 ただこういうタスク並列には限度がある、並列化原理主義者の思い描く manycore 超並列の理想からは遠い。 しかもパイプラインが深くなるとユーザの入力から画面表示までのレイテンシが長くなる上、同期にしくじって stall とかも起きやすい。 速いコアの上で直列化されたクリティカルパスがピリっと動いてくれるに越したことはない。 ぶっちゃけ今でもだいたい UI スレッドが支配的。
実例として Twitter と Instagram の UI スレッドを比較する記事を前に書いたので参照されたし。 以下はスクロールしている Twitter アプリのトレースから活発なスレッドを集めた様子:
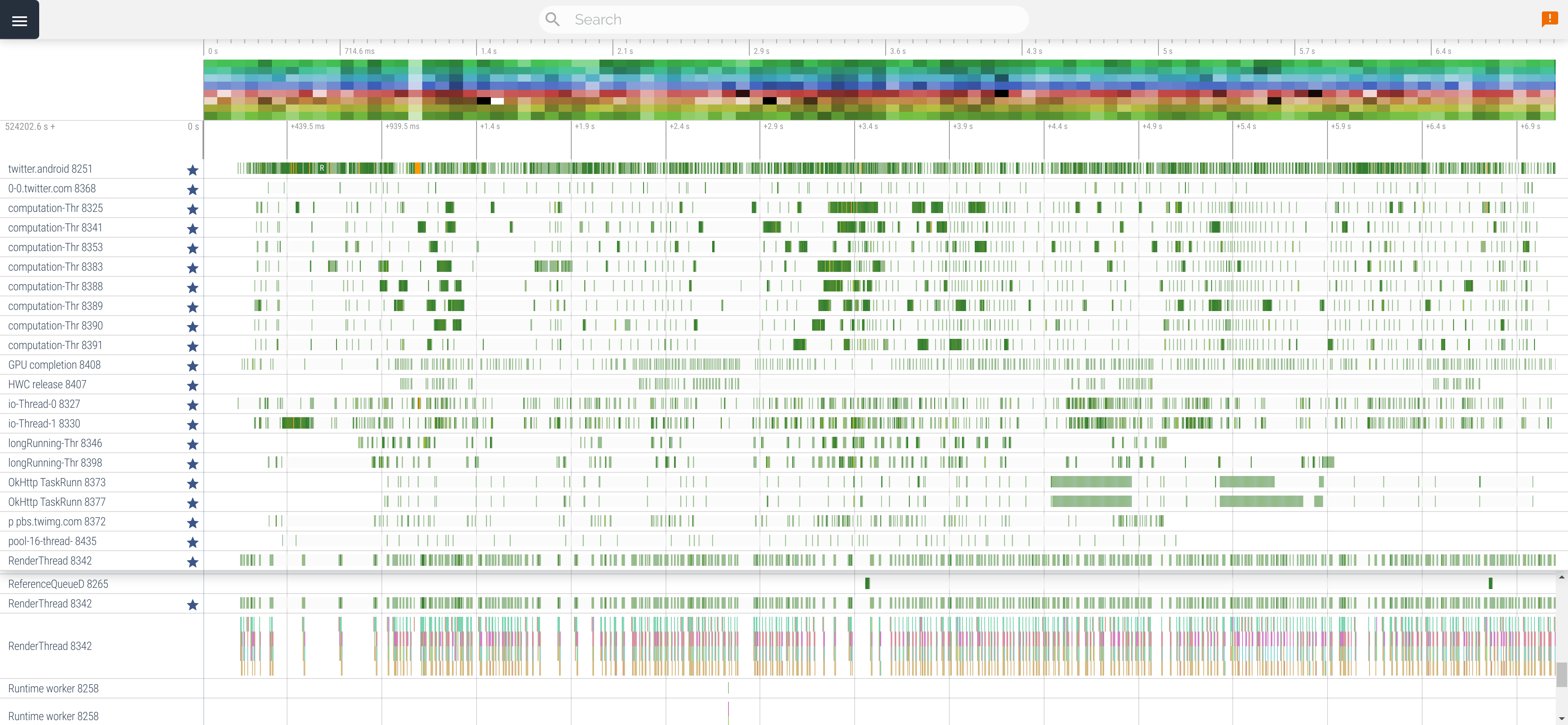
スレッド単位に行があり、緑色の部分で実際にスレッドが走っている。一番上が UI スレッド、一番下が RenderThread で、あとはそれ以外。 わりとがんばって複数スレッド使ってるけど、UI スレッドが詰まり気味なのが見て取れる。次が RenderThread. あとはスカスカ。 別に Twitter アプリの出来が特別悪いわけではなく、Android アプリというのは普通につくるとこうなる。
電話機のアーキテクチャもそうした甘えた気持ちを反映している。 最新のハイエンドチップセット Snapdragon 888 は すごい速い Cortex-X1 の “prime core” が一つ、 Cortex-A78 の “big core” が 3 つ、Cortex-A55 の “little core” が 4 つ。 これらのコアは動作クロック数も違うし、パイプラインの構成もキャッシュサイズも違う。シリコン上での専有面積も全然違う。 雑なイメージとして big と little は倍くらい性能が違う。 Prime と big も、よくわかんないけどたぶん数割は速さに差がある気がする。
つまり Snapdragon は 6+4 の 10 コアとかにするかわりに 1+3+4 = 8 コアの構成を選んだ。 お前ら manycore 並列化とかできないだろうから割は悪いけどクロック上げてキャッシュ積んでやんよ、みたいな。 なお iPhone は 2+4 の 6 コア。なのに速い。そういうことです。
ソフトウェアも過激な並列化よりでかいコアをいかす方にがんばりがち。 Android だと Linux の cpuset を使って手前のアプリ(とシステム)に速いコアを専有させている。 がんばって並列度を上げても余っているのはしょぼいコアばかり。しかも専有できないせいで混み合ってる。 下手に並列化して CPU を使い切ってもスケジューラがコアの間でタスクをたらい回すせいでキャッシュミスして遅くなるだけ。 盛り上がらない。
この構成はプログラマの甘えだけが原因でなく、 電話機のように画面がある個人向けデバイスがスループットではなくレイテンシを重視しているせいでもあると思う。 サーバサイドでバッチ処理をするようなユースケースではレイテンシを犠牲にしてスループットを上げると嬉しいことも多い。 そういうトレードオフが許されるなら並列化の選択肢も増える。 でも電話機にスループットを上げたい場面、たとえば沢山のアプリを同時にレンダリングするみたいなの、あんまりない。画面も狭いし。 スループット無視のレイテンシ重視だとタイミング調整の自由度が低く、できることが限られる。
並列化ヘビーな計算とバカパラ開拓
カメラアプリでいちばん CPU を酷使するのは起動でも画面の表示でもなく、写真の現像。 一例として HDR+ とよばれる現像アルゴリズムは 複数の RAW 画像を気の利いた方法でマージするみたいな計算をする。 データ並列な画像処理を記述できる Halide という DSL を使うなど、CPU は全力で使う。 アクセラレータも使う。
ただこいつらも 8 コアを全部使ってきちんと速くなるのかというと、キャッシュとかの都合で微妙なラインっぽい。 データ並列じゃないコードパスも結構ある。 仮に 16 コアの電話機が登場しても、写真一枚の現像処理がそれを生かしきれるのかはあまり自明でない。 自分はアルゴリズムの詳細は理解せず傍からプロファイラやトレースの出力を眺めてるだけなので実情はわからないけれど。
一方、アプリの利用統計などからユーザはシャッターボタンを連打しがちであることが知られている。 シャッターの連打によって複数の現像処理が並列に走ると CPU は簡単に埋め尽くされる。 全てのユーザが連打をするわけではないとはいえ、 ユーザに代わって連打相当の画像を用意してあげる TopShot みたいな機能は コアが沢山あれば普通に嬉しい。今はすごい複雑なコードで無理やり実装している(のでよくバグって以下愚痴省略)ところを、 もっと素朴、富豪的、あるいははまじさんのいう「バカパラ」的に実装できるようになる。
これは示唆的な事例だと思う。 つまり既存の機能を並列化して増えたコアを使い切ろうとするより、 増えたコアでバカパラ的に実現できる新しい機能/UX を模索する方が有意義なのではないか。 昔からあるソフトウェアの機能というのはそんなにコアがない時代に考えられたものなわけで、並列性がなくても仕方ない。 新しいハードウェアには新しい使い方があるはずで、それを開拓した方が差別化や競争力に繋げやすいんじゃないかなあ。 決められた問題を解くのって、パズルとしては exciting かもしれないけど縛りプレイっぽいとこないですか。
コア数増加の見通し
ところでコア数、増えるんですかね。ありのさんは 16 コアは現実で 32 コアあるかもと言っているけれど、 モバイル機器に限るとそんなに増えないという説を自分は買っている。
これはヘネパタに書いてある文字通り教科書的な見通しで、 別にユニークな洞察ではない。 ヘネパタでは Moore’s Law が終わる前に Dennard scaling が 終わってしまい困ったねという話をしている。要するに (Moore’s Law の残りカスによって) 半導体の集積度はジリジリあがっていくが、 昔は集積度によらず単位面積あたり一定だった消費電力が (Dennard scaling がおわったせいで) 集積度が増える分だけ増えていく。
CPU, 電話機だと SoC は、チップは小さいままでもどんどん電力を使うようになっていく。 でも電力予算はそんなに増えないので, チップのうちごく一部の回路しか同時に使われず、大半は寝かせて節電する。 この寝ている回路を Dark silicon という。 沢山の回路を同時に使いたい時は動作周波数を下げて節電する。
集積度アップにあわせて同一面積内の CPU のコア数を増やしかつ CPU を使い切ると、dark な部分がないため消費電力は増えてしまう。 モバイルでこれは NG. 動作周波数を下げればある程度乗り切れる (Intel の CPU は過去にそれをやった) けど、 先に書いたレイテンシ要件の厳しいモバイルで許さるだろうか。画面描画 120fps とかフレーム毎の deadline が半分になるわけで、いかにも CPU の単体性能に依存してるじゃん。
こういう電力の縛りがあるせいで manycore はそんなにこさそうとヘネパタは書いている。 かわりにどうするかというと、 TPU みたいな特定用途向けのアクセラレータ (Domain Specific Architecture) を色々積むのが良いという。 今やボトルネックは回路の集積度ではなく電力なのだから、そのぶんだぶつく回路を生かして節電しようや、みたいな話。 じっさい電話機の SoC のうち CPU が占める面積は既にだいぶ小さい。 インターネットの分析を信じるなら 1/4 未満だと思う(A14 の例) 。
こういう流れはモバイルだけかと思っていたら、 ちょっと前に Google Cloud が Intel から大物を引き抜いたから今後は SoC つくってくぞ とアナウンスしており、サーバサイドも似たようなものなかもしれない。 (自分はクラウド部門の内情は何も知らないので誤解かもしれない。) AWS も SoC は知らないけれど Nitro という名前で色々アクセラレータを作っている。
というわけで、自分は電話機やタブレットはしばらくは 8 コアで、 10 年たってもせいぜい 12 コアくらいじゃないかなとおもってます。 ラップトップも 16 コアが限度じゃないのかなあ。高い Macboook とかそのくらいあるけど、壁から電源とらないと使い物にならないよねきっと。 壁に繋ぐ計算機向けのソフトウェアは、皆様がんばってください。この文章も壁の電源で書いてますので。
CPU 屋でバイトしてたありのさんには釈迦に説法な気がしてけど、そんなかんじです。
Android は Reactive なのか
にわか業界通のしったかぶりみたいな話ばかり書いて心が痛んできた。 以下ではもうちょっとプログラマっぽいことも書いて detox したい。
Android は reactive なのか。スレッドプールに future で async でヒャッホイなのだろうか。 Kotlin の Flow とかあるので表面的にはそういう雰囲気だけど、個人的には信じてない・・・というか、できたらいいけど道は遠いよねと思っている。
Reactive な世界ではコア数にあわせてをスレッドつくると先に書いた。 現実と照らし合わせるべく先の TikTok アプリのスレッド数を数えてみる。答えを見る前に予想した数字を思い浮かべてほしい。カンでいいです。 8? 16? 32?
Perfetto UI の SQL コンソールから以下の SQL を実行する:
SELECT COUNT(*), process.name
FROM thread, process
WHERE thread.upid = process.upid
AND process.name = "com.zhiliaoapp.musically"
答え: Drumroll タララララララララ…….. …… ….. …. … .. . -> 255
これは別に TikTok が異常なわけではなく、たとえば今数えたら Twitter は 180 くらい、NYTimes は 280 くらいあった。 (補足としてとしてこれは短命スレッドも数えている。でも短命スレッドとかさ、やめろ。) しかもサーバサイドと違ってこういうアプリが 10 とか 20 とか生きてるわけです。 いくら Linux CFS が O(1) だからって現代人としていいのかこれは。8 コアしかないんだよ?
この数字だけで試合終了したくなるけど、歯を食いしばり事情を説明して参ります。
ブロッキングコールの偏在
Android, 色々なものがブロッキングコールである。
まず IPC の Binder. Android のプロセス間通信は基本ぜんぶこれです。でもね、ちょうブロックする。しかも勝手にプロセス内にスレッドプールをつくる。あなたのアプリにもこっそり binder スレッドができてます。 そしてプロセス間通信なんてそんなにないと思っているかもしれないけれど、すごい沢山ある。 たとえばちょっと画面の解像度を読もうかなと Plaform の API を呼ぶと息をするように IPC する。 これは Chrome の IPC が基本ぜんぶ async なのとは対照的である。
ただし Binder が遅いかと言われるとかならずしもそうとは言えず、 カーネルドライバとかでいろいろ小細工していて遅くはない。 でもブロッキングが基本であることに代わりはない。oneway という仕組みで非同期にできるが、 名前のとおり一方通行で値を返せないため使用範囲は限定的。
こういう platform の機能だけでなく、サードパーティのライブラリもブロックする。 Android で一番広く使われている HTTP ライブラリ OkHttp はブロッキングである。 HTTP/2 みたいな多重化プロトコルをどうやってブロッキングで実装しているのかよくわからない(たぶんコネクション単位でスレッドがある)が、とにかくブロックする。 つまりこの上に作られている REST の data binding みたいなライブラリたちは、たとえば表面的に非同期でもスタックのどこかではブロックしている。 表面的にすら非同期でないものも多い。そんなのいくら Flow をつかってもすぐスレッドプール詰まっちゃうのでは・・・。
Android で動くノンブロッキングの HTTP 実装は少ない。サーバサイドのデファクトである Netty が Android をサポートしたのは 4.1 以降。しかもテストはないからよろしくとか書いてある。実際に使われてるのは見たことがない。 Chrome の HTTP スタックを切り出した Cronet もあり、 これは Play Services についてくるので最近はそこそこ使いやすくなった。とはいえそれなりに覚悟を要する。 Envoy-Mobile とかなおさら要覚悟。
一応ちょっとだけ擁護すると、 サーバサイドの人からするとネットワークスタックを非同期にできないなら一体何を非同期にするのか疑問に思うかもしれないけれど、まあそれなりにあります。 画像のデコードみたいな重い計算がぼちぼちあるので。あと Binder IPC は HTTP の REST call に比べると当たり前だけど圧倒的に速い。 空の呼び出しなら 1ms もしない。10us とかそういう雰囲気だった記憶。なので常に問題になるわけではない。とはいえすごく遅いものもあり、そういうのがブロックすると厳しい。
ネイティブコードと Java コードの混在
Android はアプリは基本的に Java/Kotlin で書くが、platform の中は割と C++ が使われている。 あと最近の AI 系のライブラリや、それ以外でも C/C++ の資産を持ってきて使うことが多い。
最初の問題として、 C/C++ ネイティブコードは基本的に非同期とか気の利いたことしないのでブロッキングしがち。 C++ の残念さからこのスレがはじまったのを思い出してほしい。
スレッドプール分断の問題もある。
Java には Executor や
ScheduledExecutorService という
標準スレッドプール API があるのでこれを使うことが多い。しかしこれは pure Java なので C/C++ から使えない。
結果として C/C++ レイヤと Java レイヤで別々にスレッドプールをつくるという無駄が生まれる。
Kotlin や RxJava などにも似た問題があり、こいつらは Java 標準とは別のスレッドプール API を持っている。 がんばれば interop できるけど、現実的には誰も頑張らない。こうしてまた別のスレッドプールが作られる。
Conway’s Law of Thread Pool
先の RxJava / Kotlin の独自 thread pool API は、より大きな問題の一角でしかない。
より大きな問題: いくつものサードパーティライブラリたちがみな勝手に自分のスレッドプールを作る。
しかもそれぞれが何も考えず CPU のコア数だけスレッドを作ったりする。
CPU は! お前らだけのものじゃ!! ないんだぞ!!! わかってんのか!!!!
ライブラリは Executor なりその factory なりを外からさせるようにしてほしい。ほんとに。
これがサードパーティのライブラリだけならまだいいが、同一組織内でもスレッドプールを統一できてないケースがあり、 というかわたくしめのところでございますが、よく性能部門の監査人に怒られてる。俺のせいじゃねー。
先に挙げたブロッキングコールの偏在がこの解決を難しくしている: みな自分のスレッドプールを詰まらせたくない。 だから得体のしれない他人とスレッドプールを共有したがらない。基盤の不在による信頼の欠如。つらい。 ブロッキングコールが詰まる心配は杞憂ともいえず、森田はこれまでに二回 binder を介したデッドロックを報告のうえ直してもらったことがある。 どちらのケースもプールから余剰スレッドが枯渇していた。
Handler
Android platform の API はなにかと Handler オブジェクトを要求する。
Handler というのはイベントループの抽象である。イベントループというのはスレッドプールのシングルスレッド版である(語弊あり)。
だからある意味で Handler は Executor みたいなものだと言える。
でもスレッドは一つだけ。そのせいで N スレッドを M (>N) クライアントで共有するのがやりにくい。結果として人々は自分のコードでこっそり
HandlerThread をつくったりしがち。
オレオレスレッドつくるのやめてくれませんかね・・・。
Platform の雑さ
Platform の API を呼ぶと勝手に短命スレッドを作ることがよくある。なぜかというと昔からあるコードの実装が雑だからである。 Sigh.
Road Ahead
こういうのほんとなんとかしてほしいんだけど、今の所なんともなってない。
他人の実装は気にせず自分の書くコードでは Kotlin Flow なりなんなりをつかって小奇麗に書き、 それで満足しておくのは一つの態度だと思う。たぶんその方が精神衛生に良い。 でも自分はトレースをじっとみつめるお仕事をしている都合で、ランタイムの不都合な現実から文字通り目を逸らせない。 なのでいらないスレッドをちまちま削る泥臭い仕事を、精神衛生とのバランスを鑑みつつしたりしなかったりしている。
かずよしさんはそういうのはプログラマが頑張るのではなくランタイムに任せたほうがいいという。 でも Android は Go 言語じゃないからねえ・・・とかおもっていたら、 長期的には Android の問題も Go 的に解決されるかもしれないとおもわせるニュースがいくつかあった。
一つは Java の Project Loom: Java のスレッドを Go の軽量スレッド (fiber) みたいにしようという実験的なプロジェクトを Oracle が開発している。 実験的すぎて OpenJDK にマージすらされておらず、そもそも Android の Java は OpenJDK ではなく別実装の ART なので Android ART のスレッドが fiber になる日がくる見込みはそんなにないが、Java エコシステムがそっちに舵を切ったら逆らえない気もして、 長い目で淡い期待を抱いている。
もう一つは C++20 の coroutine。 Project Loom みたいなことが C++ にもおこる・・・というと雑すぎるけど Folly Future みたいのは諦めてユーザ空間に軽量な coopretive context switch を入れる。レガシー人材/コードの reactive 化という点で現実的かもしれない。
どちらも先の話なのですぐさま影響はないけれど、人類に async は早すぎたのかもと自分の中の reactive 信仰をみつめなおすきっかけにはなった。